


You Can’t Judge a Binary by Its Header: Data-Code Separation for Non-Standard ARM Binaries using Pseudo Labels
Hadjer Benkraouda, Nirav Diwan, Gang Wang
- Read: 07 Jun 2025
- Published: 12 May 2025
2025 IEEE Symposium on Security and Privacy (SP)
https://www.computer.org/csdl/proceedings-article/sp/2025/223600a036/21B7QpveAHC
Q&A (link)
What are the motivations for this work?
- See Abstract, Introduction, Section 2.
- Customized and non-standard binary formats cannot be readily processed by existing tools.
- Due to the lack of standardization and the need to keep their software proprietary, IoT vendors often create customized file formats without public documentation.
- As mentioned in section 2, inline data is also a target for this work.
What is the proposed solution?
- See Introduction, Section 3, Section 4.
- Start with data-code separation in binaries.
- Trained a ML classifier based on standard binaries, and then adapted the classifier to the target non-standard binary formats.
- Two modules:
- First module: Performs a linear sweep over the binaries and classifies each byte as code or data (using the fact that ARM binaries have fixed-length instructions).
- Second module: Performs domain adaption using unlabeled non-standarded binaries.
- The key idea is to use the initial classifier C_0 to produce pseudo labels on the non-standard binaries and then construct a set of domain-knowledge rules (e.g., define-use chain, jump/branch destination) to curate the pseudo labels. By iteratively training a new classifier (e.g., C_n) and performing pseudo-label correction, gradually improve the classifier’s performance on non-standard binaries.
- For standard binaries, loadstar only requires labels on the data/code sections (coarse- grained) but not necessarily labels on inline data.
- The high-level intuitions of Loadstar are two-fold.
- First, while the code sections follow the language-specific patterns/semantics, the data sections do not. Such differences can be reflected in the characteristics of forcefully decoded instructions.
- Second, the difference between code and data may not be the same between standard and non-standard binary formats; but a set of domain knowledge could serve as the “invariant” (that does not change across binary formats). Such domain knowledge can help to adapt a classifier trained for standard binaries to work on a non-standard binary format.
- Overview.
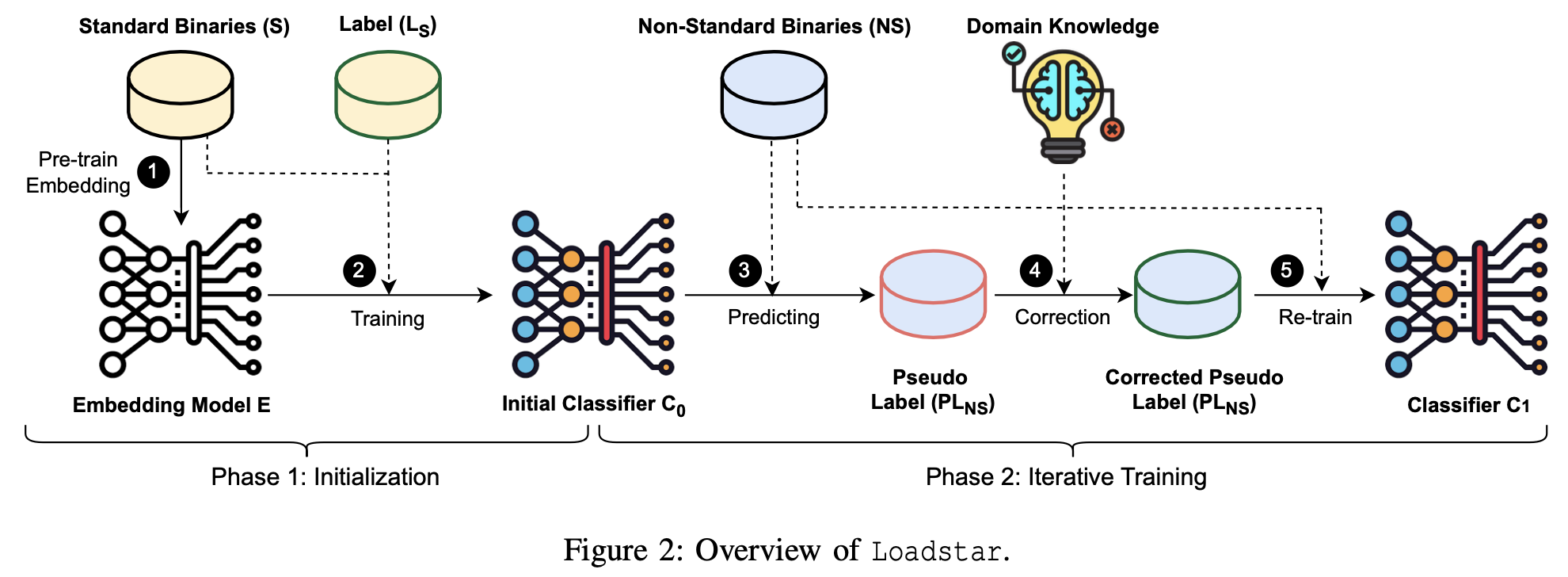
- Primary design uses an embedding model specifically trained for (standard) binaries and uses an LSTM model to build the classifier (to balance accuracy and efficiency). Also mentioned in appendix an alternative way involving using BERT.
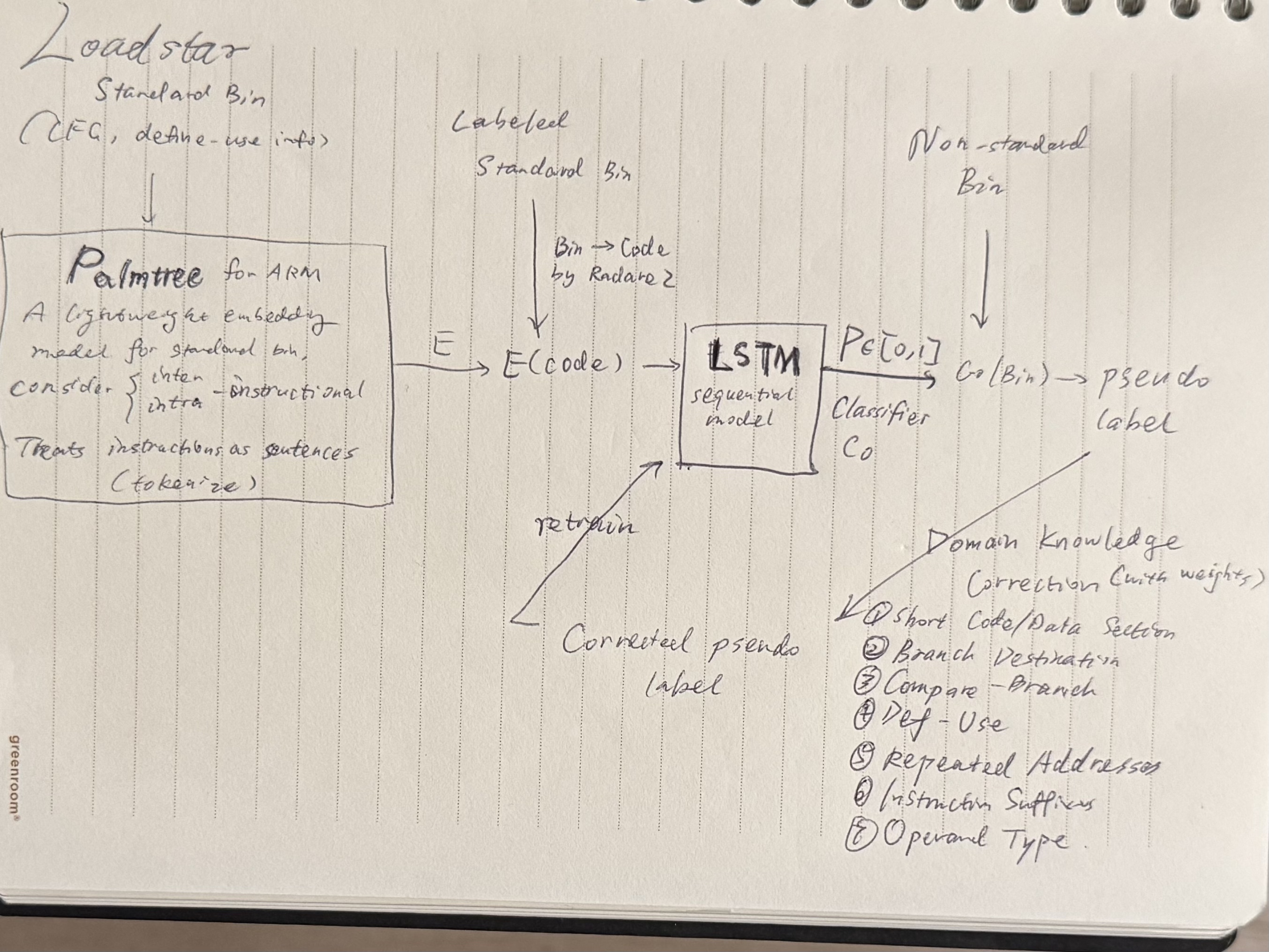
- I drew a diagram further illustrating the process.
What is the work’s evaluation of the proposed solution?
See Introduction, Section 5.
- Focused on PLC (Programmable Logic Controller) binaries under the ARM instruction set architecture.
- Use XDA as the baseline. XDA doesn’t perform code and data separation therefore adapt their instruction boundary detection task for this purpose.
What is your analysis of the identified problem, idea and evaluation?
Choosing ARM is indeed a good idea.
What are the contributions?
- See Introduction.
- A system called Loadstar, it is a pseudo-label-based learning model that performs data-code separation for non-standard binaries.
What are future directions for this research?
- See Section 6.
- Explore how Loadstar can work with other ISAs.
What questions are you left with?
NONE
What is your take-away message from this paper?
- See Introduction, Section 5.
- Given a non-standard binary, Ghidra will load it as a raw binary, while Radare2 performs a linear sweep disassembly where it assumes all bytes are code.
- The “Short Code/Data Section” rule is the most effective one to correct pseudo labels, this is because the initial classifier trained on standard binaries predicts many short data/code sections.
- Rules based on logical assertion of code behaviors (e.g., Branch Destination, Compare-Branch, and Define-Use) perform well and positively influence pseudo-label accuracy. In contrast, rules based on statistical properties, especially those that describe statistically “uncommon” code behaviors (e.g., Instruction Suffixes, and Operand Type), often produce false labels.
- In practice, users can train a global model for different types of non-standard binaries of interest, by tuning with a diverse set of unlabeled non-standard binaries in those target formats.
Written on